


What should we make of large language models (LLMs)? It’s quite literally a billion-dollar question.
It’s one addressed this week in an analysis by former OpenAI employee Leopold Aschenbrenner, in which he makes the case that we may be only a few years away from large language model-based general intelligence that can be a “drop-in remote worker” that can do any task human remote workers do. (He thinks that we need to push ahead and build it so that China doesn’t get there first.)
His (very long but worth reading) analysis is a good encapsulation of one strand of thinking about large language models like ChatGPT: that they are a larval form of artificial general intelligence (AGI) and that as we run larger and larger training runs and learn more about how to fine-tune and prompt them, their notorious errors will largely go away.
It’s a view sometimes glossed as “scale is all you need,” meaning more training data and more computing power. GPT-2 was not very good, but then the bigger GPT-3 was much better, the even bigger GPT-4 is better yet, and our default expectation ought to be that this trend will continue. Have a complaint that large language models simply aren’t good at something? Just wait until we have a bigger one. (Disclosure: Vox Media is one of several publishers that has signed partnership agreements with OpenAI. Our reporting remains editorially independent.)
Among the most prominent skeptics of this perspective are two AI experts who otherwise rarely agree: Yann LeCun, Facebook’s head of AI research, and Gary Marcus, an NYU professor and vocal LLM skeptic. They argue that some of the flaws in LLMs — their difficulty with logical reasoning tasks, their tendency toward “hallucinations” — are not vanishing with scale. They expect diminishing returns from scale in the future and say we probably won’t get to fully general artificial intelligence by just doubling down on our current methods with billions more dollars.
Who’s right? Honestly, I think both sides are wildly overconfident.
Scale does make LLMs a lot better at a wide range of cognitive tasks, and it seems premature and sometimes willfully ignorant to declare that this trend will suddenly stop. I’ve been reporting on AI for six years now, and I keep hearing skeptics declare that there’s some straightforward task LLMs are unable to do and will never be able to do because it requires “true intelligence.” Like clockwork, years (or sometimes just months) later, someone figures out how to get LLMs to do precisely that task.
I used to hear from experts that programming was the kind of thing that deep learning could never be used for, and it’s now one of the strongest aspects of LLMs. When I see someone confidently asserting that LLMs can’t do some complex reasoning task, I bookmark that claim. Reasonably often, it immediately turns out that GPT-4 or its top-tier competitors can do it after all.
I tend to find the skeptics thoughtful and their criticisms reasonable, but their decidedly mixed track record makes me think they should be more skeptical about their skepticism.
We don’t know how far scale can take us
As for the people who think it’s quite likely we’ll have artificial general intelligence inside a few years, my instinct is that they, too, are overstating their case. Aschenbrenner’s argument features the following illustrative graphic:
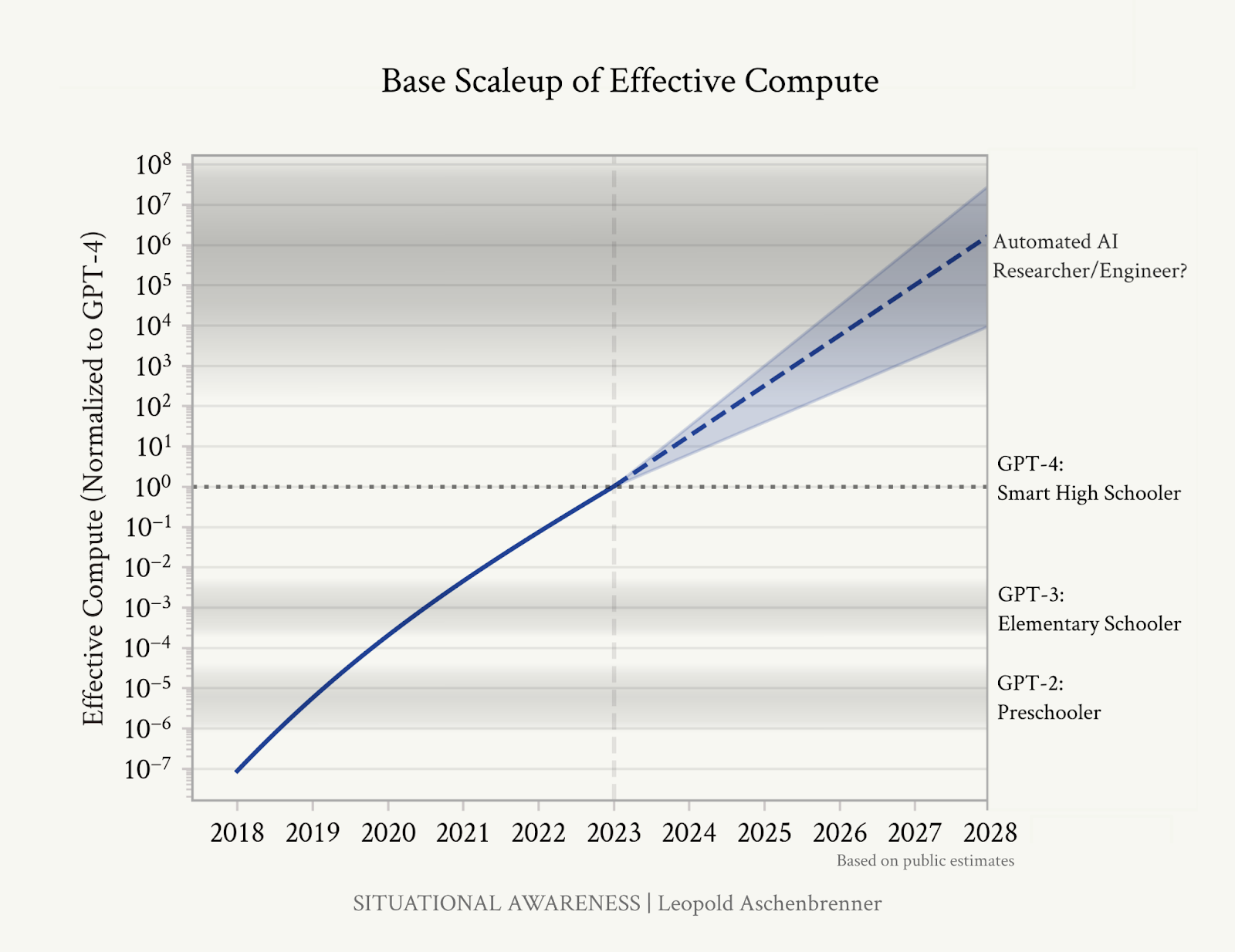
I don’t want to wholly malign the “straight lines on a graph” approach to predicting the future; at minimum, “current trends continue” is always a possibility worth considering. But I do want to point out (and other critics have as well) that the right-hand axis here is … completely invented.
GPT-2 is in no respects particularly equivalent to a human preschooler. GPT-3 is much much better than elementary schoolers at most academic tasks and, of course, much worse than them at, say, learning a new skill from a few exposures. LLMs are sometimes deceptively human-like in their conversations and engagements with us, but they are fundamentally not very human; they have different strengths and different weaknesses, and it’s very challenging to capture their capabilities by straight comparisons to humans.
Furthermore, we don’t really have any idea where on this graph “automated AI researcher/engineer” belongs. Does it require as many advances as going from GPT-3 to GPT-4? Twice as many? Does it require advances of the sort that didn’t particularly happen when you went from GPT-3 to GPT-4? Why place it six orders of magnitude above GPT-4 instead of five, or seven, or 10?
“AGI by 2027 is plausible … because we are too ignorant to rule it out … because we have no idea what the distance is to human-level research on this graph’s y-axis,” AI safety researcher and advocate Eliezer Yudkowsky responded to Aschenbrenner.
That’s a stance I’m far more sympathetic to. Because we have very little understanding of which problems larger-scale LLMs will be capable of solving, we can’t confidently declare strong limits on what they’ll be able to do before we’ve even seen them. But that means we also can’t confidently declare capabilities they’ll have.
Prediction is hard — especially about the future
Anticipating the capabilities of technologies that don’t yet exist is extraordinarily difficult. Most people who have been doing it over the last few years have gotten egg on their face. For that reason, the researchers and thinkers I respect the most tend to emphasize a wide range of possibilities.
Maybe the vast improvements in general reasoning we saw between GPT-3 and GPT-4 will hold up as we continue to scale models. Maybe they won’t, but we’ll still see vast improvements in the effective capabilities of AI models due to improvements in how we use them: figuring out systems for managing hallucinations, cross-checking model results, and better tuning models to give us useful answers.
Maybe we’ll build generally intelligent systems that have LLMs as a component. Or maybe OpenAI’s hotly anticipated GPT-5 will be a huge disappointment, deflating the AI hype bubble and leaving researchers to figure out what commercially valuable systems can be built without vast improvements on the immediate horizon.
Crucially, you don’t need to believe that AGI is likely coming in 2027 to believe that the possibility and surrounding policy implications are worth taking seriously. I think that the broad strokes of the scenario Aschenbrenner outlines — in which an AI company develops an AI system it can use to aggressively further automate internal AI research, leading to a world in which small numbers of people wielding vast numbers of AI assistants and servants can pursue world-altering projects at a speed that doesn’t permit much oversight — is a real and scary possibility. Many people are spending tens of billions of dollars to bring that world about as fast as possible, and many of them think it’s on the near horizon.
That’s worth a substantive conversation and substantive policy response, even if we think those leading the way on AI are too sure of themselves. Marcus writes of Aschenbrenner — and I agree — that “if you read his manuscript, please read it for his concerns about our underpreparedness, not for his sensationalist timelines. The thing is, we should be worried, no matter how much time we have.”
But the conversation will be better, and the policy response more appropriately tailored to the situation, if we’re candid about how little we know — and if we take that confusion as an impetus to get better at measuring and predicting what we care about when it comes to AI.
A version of this story originally appeared in the Future Perfect newsletter. Sign up here!
